Керування корпоративними даними: оптимізація життєвого циклу даних у бізнесі
Щодня об’єм корпоративних даних стрімко збільшується. Всю цю інформацію необхідно правильно збирати, структурувати й зберігати. Як це робити? Відповіді на ці запитання розглянемо з Євгеном Руденком, консультантом з рішень у сфері Data Science у NIX.
Сучасні компанії генерують надто багато даних, ніж можуть ефективно обробити.
Зазвичай близько 20% даних охоплюють 80% ключових бізнес-процесів. Щоб уникнути витрати великої кількості зусиль на спробу охопити всі наявні процеси, компанії повинні встановлювати пріоритети в обробці даних.
Перший крок — обрати правильні дані та сфокусуватися саме на них. Це може бути зроблено кількома способами:
- Взаємодіяти з близькими бізнес-процесами. Це стосується завдань, які виконують кілька відділів або філій компанії. У таких випадках часто виникають проблеми, такі як дублювання інформації або помилки у введенні даних. Необхідно зменшити ручну обробку даних, щоб оптимізувати роботу команди.
- Звернути увагу на відділи, що співпрацюють. Коли один відділ слідує за процесом в іншому, може виникнути складний ланцюг передачі даних між відділами. Це може призвести до помилок під час обміну та обробки інформації.
- Співпрацювати з партнерами. Кожна компанія-партнер має свої формати даних і правила роботи з ними. Тому під час інтеграції продуктів різних бізнесів під час обміну або об’єднання даних необхідно перевірити відсутність дублів і забезпечити збіг форматів.
Цифрова трансформація бізнесу: виклики та підходи
У світовій практиці вже закріпилися два ефективних підходи до цифрування корпоративних даних:
- Традиційний підхід, який зазвичай починається з топменеджменту. Керівники визнають необхідність оптимізації, яка потім передається на рівень менеджерів середньої ланки. Ті, своєю чергою, визначають команду, яка буде реалізовувати ідею. Однак нижчі рівні часто не розуміють важливості такої задачі, що може сповільнити зміни й навіть призвести до конфліктів.
- Ініціативний підхід, де все починається з відгуку користувача щодо продукту. Потім працівник, що спілкується з клієнтом, ініціює зміни у процесах на основі отриманого фідбеку.
Ефективне управління даними передбачає виконання ряду обов’язкових умов:
- Видимість та доступність. Ця умова стосується швидкості та зручності пошуку даних. Найпростіше підвищити рівень видимості можна за допомогою використання міток, які дозволяють легко фільтрувати та обробляти великі обсяги інформації.
- Надійність. Гарантувати надійність джерела даних — це важливий аспект управління даними. Без цього, неможливо ефективно керувати та інтегрувати дані з іншими джерелами. До цього необхідно мати чітке уявлення, звідки походять дані, і переконатися, що вони представлені у відповідному форматі.
- Безпека. Для більшості компаній безпека даних є однією з найважливіших складових. Особливо це стосується організацій, що працюють з особистими даними клієнтів, фінансовими інформацією і даними про стан здоров’я людей. Вимоги щодо зберігання інформації стають все більш жорсткими з часом.
- Масштабованість. Вона дозволяє автоматизувати повторювані процеси та позбавитися від дублювання даних при їх обробці різними відділами та працівниками. Це призводить до покращення узгодженості даних та зменшення кількості помилок.
Приклад розробки BI-платформи для аналізу даних на AWS
Недавно наша команда стикнулася з завданням вдосконалити маркетингову ефективність та забезпечити більшу доступність даних для одного з клієнтів — мережі супермаркетів. Однак ресурси для реалізації були обмеженими.
Ми вирішили піти на компроміс і не використовувати готові рішення з обмеженнями, а замість цього розробити власний інструмент в хмарному середовищі. На цьому етапі ми взяли за основу послуги Amazon, такі як сховище S3, засоби обробки даних та лямбда-тригери. Також ми використовували AWS Glue для обробки даних і Redshift для їх зберігання. В результаті ми досягли великої гнучкості в реалізації різних бізнес-потреб при низькому рівні витрат.
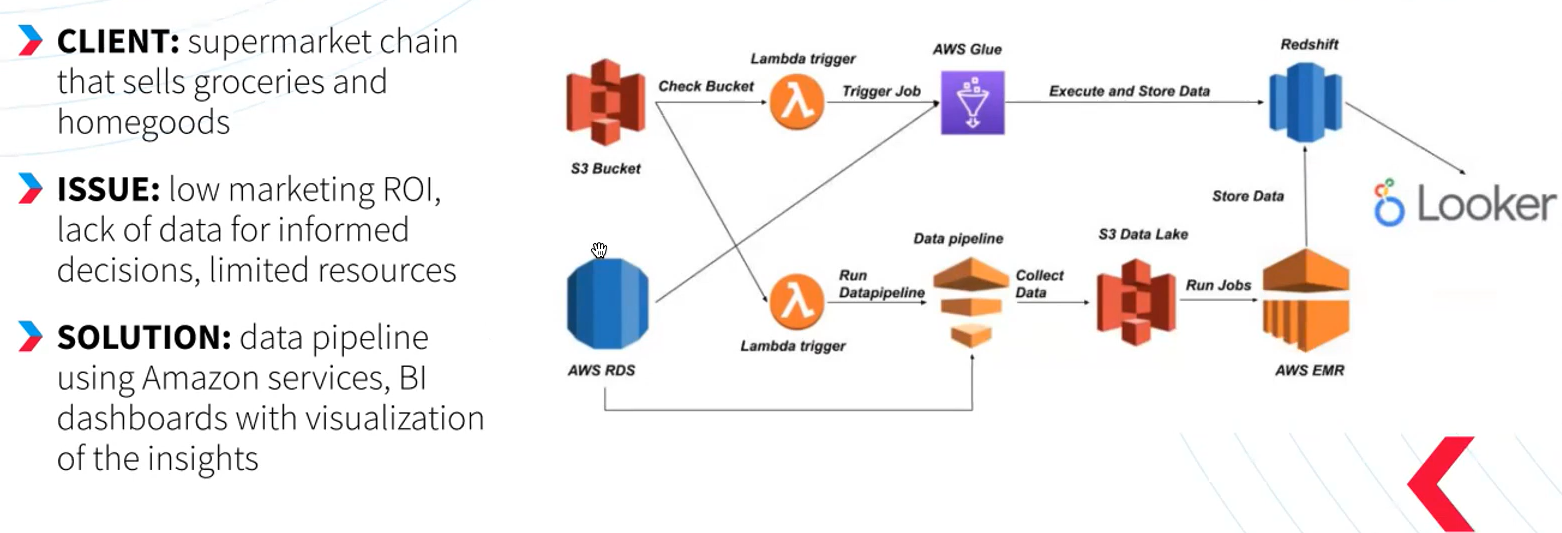
Наша система створила потік даних, починаючи з того, що магазин отримував дані з різних джерел, такі як пропозиції, замовлення, продажі та клієнти. Ці дані оброблялися кількома кроками за визначеною схемою. На завершальному етапі дані виводилися на BI-панель, де ми могли аналізувати демографічний розподіл клієнтів.
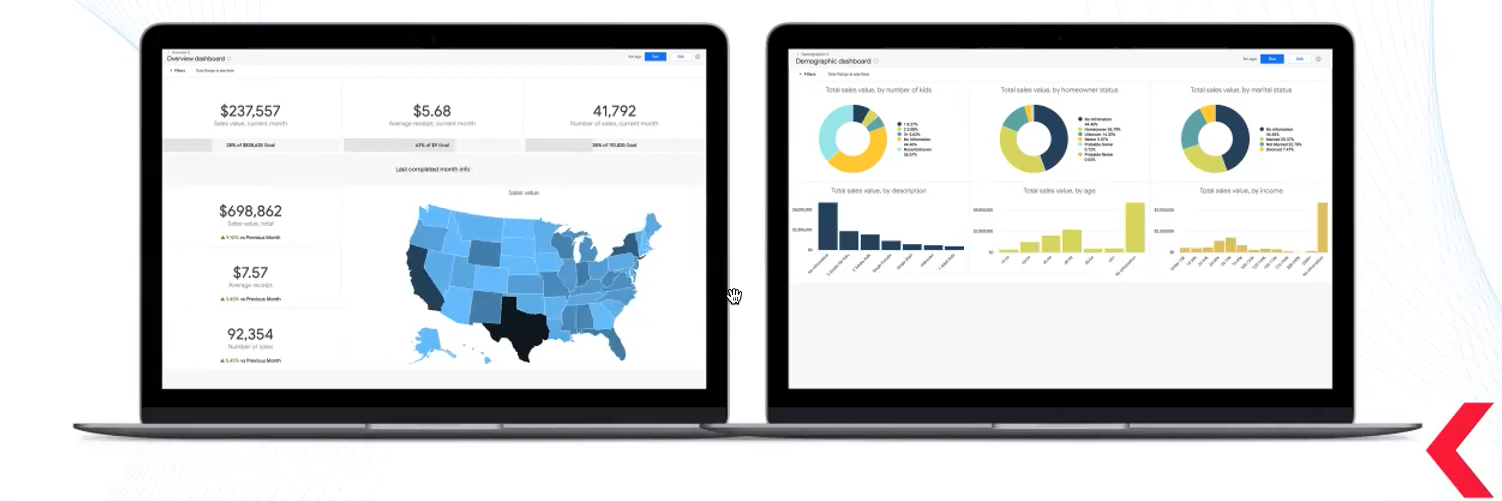
Це спростило сегментацію та допомогло в створенні персоналізованих маркетингових стратегій, відстеженні результатів та оптимізації рекламних кампаній.
Переваги використання штучного інтелекту у сфері аналізу даних
Сьогодні без впровадження цієї технології стає складно досягти успіху в умовах жорсткої конкуренції. Зазвичай для цього використовуються три рівні підходу:
- Рівень даних. Це базовий рівень, де здійснюється збір та підготовка даних для подальшого аналізу.
- Рівень аналітики та розробки. На цьому етапі спеціалісти проводять аналіз даних і створюють візуалізацію. Це може бути особа, яка впроваджує зміни за власною ініціативою.
- Рівень ухвалення рішень. Тут відбувається модифікація та оптимізація продукту. Чим більше даних доступно, тим глибше може бути аналітика, а отже, і більше можливостей для внесення змін.
Окрім описового аналізу, коли ви чітко бачите всі дані, існує можливість прогнозування. Завдяки розширеній обробці даних і машинному навчанню, можна передбачити очікувані результати, такі як потреби в обслуговуванні або зміни в продажах протягом пів року. Це дозволяє отримати нові дані, які є критичними для ухвалення правильних бізнес-рішень.
Приклад вдосконалення процесу автоматизації роботи з даними за допомогою інструментів штучного інтелекту
Наш клієнт — провідна компанія в галузі роботизації бізнес-процесів (RPA) — стикнувся з проблемами щодо інфраструктури даних. Замовник шукав спосіб оптимізувати свою систему для підвищення конкурентоспроможності.
Ніксова команда допомогла спланувати та впровадити перехід до хмарної інфраструктури та вдосконалити автоматизовані пайплайни CI/CD. Ми також додали інноваційні функції до інструментів RPA, зокрема автоматизовану платформу для смартаналітики з дашбордами, які дозволяють користувачам налаштовувати фільтрацію даних за власними потребами. Наприклад, вони можуть перетягувати таблиці з графіками та створювати власні середовища для аналізу даних.
Крім цього, ми розробили інтелектуальну систему обробки документів з оптичним розпізнаванням символів. Це дозволило структурувати корпоративні документи, які раніше були неструктурованими. Ми також впровадили механізм комп’ютерного бачення для фіксації User Flow, що дозволило системі автоматично заміняти ці процеси автоматизованими сценаріями. Це вимкнуло від праці ряд співробітників і дозволило їм зосередитися на більш креативних завданнях.
Як можна побачити, ефективна робота з даними значно підвищує продуктивність бізнесу і робочу ефективність працівників. Головне — встановити правильні пріоритети та мати підтримку висококваліфікованих фахівців. Тоді побудова комплексної системи управління даними принесе компанії відчутну користь.

