Поради дата-інженера, як нестандартно автоматизувати таргетовану рекламу
Перш ніж переходити до розгляду теми, пригадаймо два терміни.
- User Acquisition — це процес пошуку нових клієнтів, привернення уваги до сайту/застосунку за допомогою реклами.
- Ретаргетинг — це дія реклами на аудиторію, яка вже знайома з продуктом. Акцент зміщено на користування певним сайтом чи застосунком.
Переходимо до проєкту. Яка мета стояла перед нами?
Нікси мали вдосконалити масштабну систему таргетованої реклами, яка б модифікувала та оптимізувала User Acquisition і ретаргетинг. В середньому система обробляє майже мільйон реквестів за секунду.
Сервіс побудований на багатьох модулях, тож стек технологій дуже різноманітний:
- Для хендлінгу бід-реквестів ми використовували бідер, головний модуль хендлінгу реквестів, написаний на Scala. Для його API беремо стек Akka-бібліотек. Також вони потрібні для інших модулів на Scala.
- Для передачі бід-реквестів — в якості меседж-брокера обрали Apache Kafka. Він може не лише передавати іншим модулям реквести про ставки, а й витримувати значне навантаження у режимі реального часу.
- Для обробки масивів даних — застосовуємо Spark Job для різних цілей з обробки таких великих обсягів інформації.
- Для фронтенду використовуємо Angular. Сервіс, який керує API фронтенду, написаний на Java із застосуванням фреймворку Spring.
- Для прогнозування ставки потрібен потужний інструмент передбачення оптимального рівня ціни за рекламний показ. З цим нам допоміг Python із PMML-моделями.
- Для збереження інформації — MySQL обрали для даних, які мають зберігатися більше тижня, для часто змінюваних даних та кешу — Aerospike та Redis, а для аналітичних даних — Apache та Druid.
- Для роботи з логами взяли Elasticsearch. Платформа генерує величезну кількість логів. Із таким масивом він найкраще впорається.
- Вебсервіси. Для деплою та інших пов’язаних задач ми підключили чимало AWS-сервісів: EC2, ECS, EMR, S3, S3 Glacier тощо.
Найбільше нас зацікавили нетипові модулі: Reporting UI та Stopper.
Як працює Reporting UI
Цей модуль відправляє репорти, але реалізований механізм відрізняється від звичних методів. Зазвичай репорти з важливою бізнес-інформацією надходять на email або різні BA-інструменти.
У нашому випадку репорти можна надсилати ще у Slack. У цьому месенджері відбувається вся комунікація щодо проєкту.
Ми додали й інші функції:
- можливість отримувати репорт про прибуток у каналі в Slack у вигляді деталізованої діаграми;
- підписка на потрібні репорти;
- інтеграція з командами в чаті, щоб за допомогою ботів згенерувати репорт прибутку за конкретним SSP (цей спосіб доставки репортів оцінили і бізнес-аналітики, і замовник).
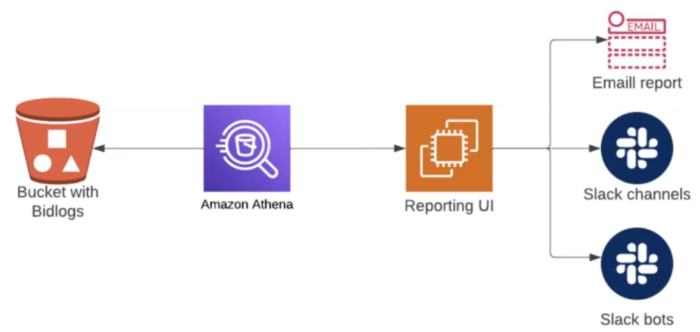
Технічна реалізація модуля не складна. Спочатку ми робимо запит на Amazon Athena для отримання потрібної інформації з бід-логів. Ці дані приводимо у необхідні для репортів формати. Далі залишається обрати шлях розсилки: на email, у Slack-канал або чат-бот (якщо є відповідна команда).
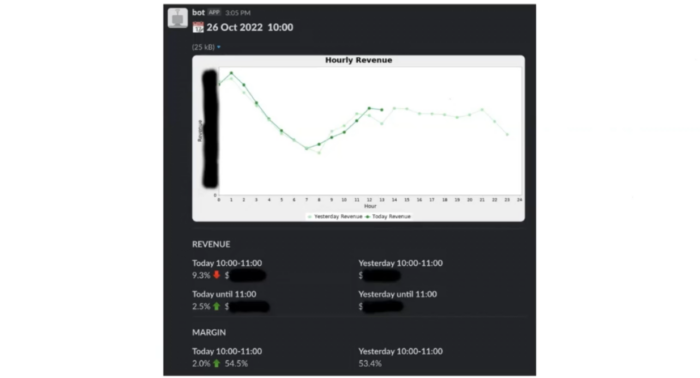
На ілюстрації нижче — приклад такого репорту. Тут наведено графік із даними про прибуток і деякими цифрами. Дві лінії позначають дані за сьогодні та за вчора.
Інший цікавий модуль — це Stopper
У певний момент кількість клієнтів сервісу різко зросла. Щоб підвищити гнучкість конфігурації та скейлінгу системи з’явилася потреба перейти на більш модульну архітектуру. Але після апдейту в модулях виникали помилки, що призводило до втрат грошей. Зазвичай зафіксувати ці проблеми просто, адже у нас велика кількість аналітичних даних і метрик. Тож потрібно було зупинити бідер та виправити баг. Тоді ми вирішили зробити високорівневий Exception Handler, наш Stopper. Його мета — автоматизувати ідентифікацію проблем і зупинку хендлінгу реквестів.
Реалізація Stopper доволі проста:
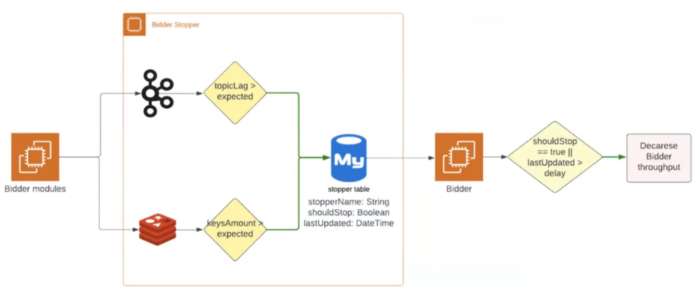
Як правило, для відстеження проблем ми дивимося на кількість івентів і лаг деяких топіків на Kafka. Наш модуль або дивиться на лаг, або зчитує кількість івентів, які проходять через топік.
Оскільки ми розуміємо нормативні показники, то можемо виставляти мінімальні та максимальні рівні для топіків і таймаут затримки. У разі перевищення або нестачі івентів дані про ці проблеми відправляються до MySQL-таблиці. Саме там Stopper перевіряє інформацію та вирішує: зупиняти хендлінг реквестів чи ні.
Також на схемі ви могли помітити Redis. Це пояснюється тим, що зараз ми тестуємо зупинку реквестів ще й за цією базою даних. Якщо кількість ключів стане критично великою або сильно зменшиться, система має зробити все те саме, що і для Kafka.
Поради наостанок
1. Не заганяйте себе в рамки одного рішення
Поєднуйте непоєднуване й збільшуйте можливості системи. Зрештою ви точно заощадите гроші, що цінує бізнес.
2. Використовуйте звичні підходи та інструменти у незвичний спосіб
Ми спробували відправляти важливу BA-інформацію у месенджери. Це не традиційно у більшості проєктів, але від того й цікаво. І що важливо — ефективно!
3. Автоматизуйте все, що можна
Коли здається, що це неможливо — шукайте варіанти реалізації. Ми в цьому впевнились на прикладі Stopper’у, який звільнив частину ресурсів наших фахівців.

